Apache HTTP Server Version 2.2

Apache HTTP Server Version 2.2

This document refers to a legacy release (2.2) of Apache httpd. The active release (2.4) is documented here. If you have not already upgraded, please follow this link for more information.
You may follow this link to go to the current version of this document.
This document discusses some of the technical details of mod_rewrite and URL matching.

The internal processing of this module is very complex but needs to be explained once even to the average user to avoid common mistakes and to let you exploit its full functionality.
First you have to understand that when Apache processes a
HTTP request it does this in phases. A hook for each of these
phases is provided by the Apache API. Mod_rewrite uses two of
these hooks: the URL-to-filename translation hook which is
used after the HTTP request has been read but before any
authorization starts and the Fixup hook which is triggered
after the authorization phases and after the per-directory
config files (.htaccess) have been read, but
before the content handler is activated.
So, after a request comes in and Apache has determined the corresponding server (or virtual server) the rewriting engine starts processing of all mod_rewrite directives from the per-server configuration in the URL-to-filename phase. A few steps later when the final data directories are found, the per-directory configuration directives of mod_rewrite are triggered in the Fixup phase. In both situations mod_rewrite rewrites URLs either to new URLs or to filenames, although there is no obvious distinction between them. This is a usage of the API which was not intended to be this way when the API was designed, but as of Apache 1.x this is the only way mod_rewrite can operate. To make this point more clear remember the following two points:
.htaccess files, although these are reached
a very long time after the URLs have been translated to
filenames. It has to be this way because
.htaccess files live in the filesystem, so
processing has already reached this stage. In other
words: According to the API phases at this time it is too
late for any URL manipulations. To overcome this chicken
and egg problem mod_rewrite uses a trick: When you
manipulate a URL/filename in per-directory context
mod_rewrite first rewrites the filename back to its
corresponding URL (which is usually impossible, but see
the RewriteBase directive below for the
trick to achieve this) and then initiates a new internal
sub-request with the new URL. This restarts processing of
the API phases.
Again mod_rewrite tries hard to make this complicated step totally transparent to the user, but you should remember here: While URL manipulations in per-server context are really fast and efficient, per-directory rewrites are slow and inefficient due to this chicken and egg problem. But on the other hand this is the only way mod_rewrite can provide (locally restricted) URL manipulations to the average user.
Don't forget these two points!
Now when mod_rewrite is triggered in these two API phases, it reads the configured rulesets from its configuration structure (which itself was either created on startup for per-server context or during the directory walk of the Apache kernel for per-directory context). Then the URL rewriting engine is started with the contained ruleset (one or more rules together with their conditions). The operation of the URL rewriting engine itself is exactly the same for both configuration contexts. Only the final result processing is different.
The order of rules in the ruleset is important because the
rewriting engine processes them in a special (and not very
obvious) order. The rule is this: The rewriting engine loops
through the ruleset rule by rule (RewriteRule directives) and
when a particular rule matches it optionally loops through
existing corresponding conditions (RewriteCond
directives). For historical reasons the conditions are given
first, and so the control flow is a little bit long-winded. See
Figure 1 for more details.
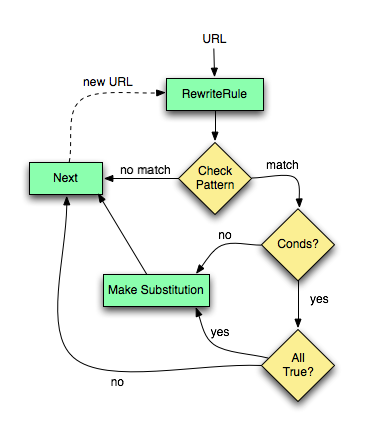
Figure 1:The control flow through the rewriting ruleset
As you can see, first the URL is matched against the Pattern of each rule. When it fails mod_rewrite immediately stops processing this rule and continues with the next rule. If the Pattern matches, mod_rewrite looks for corresponding rule conditions. If none are present, it just substitutes the URL with a new value which is constructed from the string Substitution and goes on with its rule-looping. But if conditions exist, it starts an inner loop for processing them in the order that they are listed. For conditions the logic is different: we don't match a pattern against the current URL. Instead we first create a string TestString by expanding variables, back-references, map lookups, etc. and then we try to match CondPattern against it. If the pattern doesn't match, the complete set of conditions and the corresponding rule fails. If the pattern matches, then the next condition is processed until no more conditions are available. If all conditions match, processing is continued with the substitution of the URL with Substitution.
